Firestore上のデータをBigQueryとLookerStudioで分析する

- プロダクト
 Takuya Takubo
Takuya Takubo こんにちは。エンスポーツでプロダクトマネージャーをしている田窪です。
エンスポーツでは現状、バックエンドにはFirebaseのサービスを主に使用しており、とくにデータベースにはFirestoreを使用しています。このような環境下でアプリ上のデータを分析するためには、FirestoreのデータをBigQueryに流すか、イベントをGA4に飛ばすか、いずれかの選択肢になることが多いかと思います。
今回はFirestore上のデータをBigQueryに流し、BigQueryのデータをLookerStudioを介して分析する方法についてまとめました。
Firestore上のデータをBigQueryへリアルタイムにインポートする
Firestore上のデータをBigQueryにインポートする方法は、主に2つあります。
- バックアップファイルを作成して手動でインポートする
- 拡張機能「Stream Firestore to BigQuery」を使用してインポートする
このうち私が選んだのは、後者の拡張機能を利用した方法です。Stream Firestore to BigQueryを使用すると、だいたい5分ごとに自動的に追加データをBigQueryへ流し込んでくれるため、毎回手動でインポートする手間が不要になります。
というわけで今回は、拡張機能「Stream Firestore to BigQuery」を使用してインポートする方法について解説します。
1. Extensionsから「Stream Firestore to BigQuery」を探す
まずはFirebaseのサイドバーから「Extensions」を開きましょう。Extensionsの画面最下部にある「拡張機能を探す」をクリックすると「Firebase Extensions Hub」が表示されます。
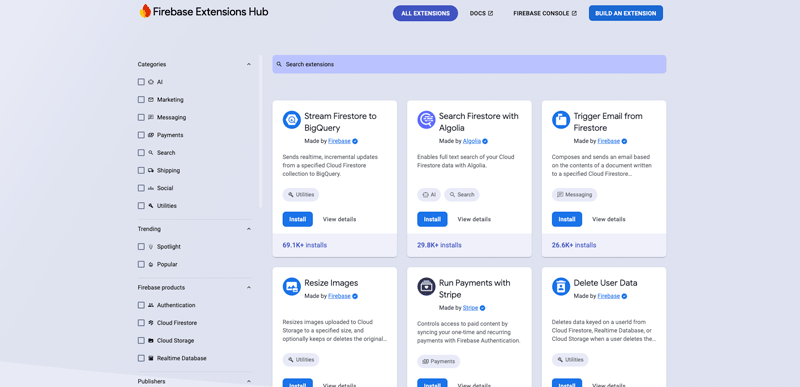
この中から「Stream Firestore to BigQuery」をインストールします。よく使われているため、だいたい左上に表示されていますが、見つからなければ検索バーから検索してください。
install を押すとインストール先のプロジェクト選択画面に遷移しますので、任意のプロジェクトを選択します。
2. 拡張機能のインスタンスIDを設定する
インストールするプロジェクトを選択すると、下記のような画面になります。
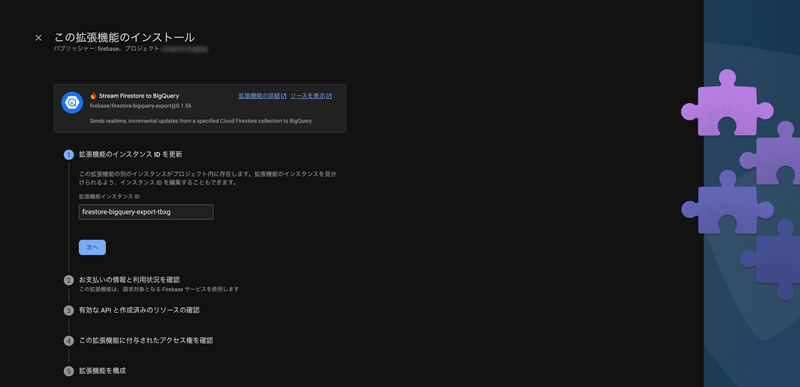
最初の項目「拡張機能のインスタンス ID を更新」で設定したIDが、Extensionsの一覧画面でも表示されます。
Stream Firestore to BigQueryは、BigQueryにデータを流すコレクション単位でインストールします。例えばusersコレクションとlikeコレクションをBigQueryに流したい場合は、Stream Firestore to BigQueryを2つインストールすることになりますから、例えばコレクション名を末尾につけておいて、後から見てわかるように運用することをお勧めします。
usersコレクションの場合はfirestore-bigquery-export-users、likeコレクションの場合はfirestore-bigquery-export-likeにするなど。
3. 拡張機能を構成する
インスタンスIDを設定したら、次にお支払い情報、有効なAPI、アクセス権の確認項目が出ますが「次へ」を押すだけです。
その後「拡張機能を構成」に入ると、以下の内容を順番に入力していくことになります。
Cloud Functions location
この拡張機能をインストールすると、Functionsに関数が作成されます。Functionsのどのロケーションに作成するのか選びましょう。
BigQuery Dataset location
BigQueryはデータセット単位でロケーションが設定されます。基本的にはFirestoreやFunctionsと合わせておいて良いのではないでしょうか。私はそうしています。
BigQuery Project ID
今回のデータをインポートするBigQueryのプロジェクトIDを入力します。デフォルトではFirebaseのプロジェクトIDと同じものが入力されており、とくに指定がなければそのままで良いかと思います。
Collection path
BigQueryへインポートするコレクション名を入力します。
Enable logging failed exports
FirestoreからBigQueryへデータを流す際、仮に失敗した場合にログを残すか否かを選択します。とにかく正確なデータを扱う必要がある場合はYesにしておくと、後から調査がしやすくなります。
Enable Wildcard Column field with Parent Firestore Document IDs
最終的にBigQuery側でビューを作成するため、基本的にはNoで問題ないかと思いますが、必要に応じて変更してください。
Dataset ID
BigQuery側で使用したいデータセット名を記述します。存在しなければ作成されます。
Table ID
データセット内に作成するテーブル名を記述します。すでに存在している場合は上書きされます。
BigQuery SQL table Time Partitioning option type
省略可の項目です。
BigQueryにおいて、データの取り込み時間に基づいたタイムパーテーションを貼る際に設定します。
パーテーションを貼っておくと、データが大規模になってきた際に効率よくクエリできる可能性があります。
BigQuery Time Partitioning column name
省略可の項目です。
「BigQuery SQL table Time Partitioning option type」を設定した場合のみ設定する、パーテーション用のタイムスタンプフィールドを指定する項目です。
空白にしておくと、デフォルト設定として疑似列 _PARTITIONTIMEになります。
Firestore Document field name for BigQuery SQL Time Partitioning field option
省略可の項目です。
任意のフィールドにパーテーションを設定したい場合に指定します。
BigQuery SQL Time Partitioning table schema field(column) type
省略可の項目です。
任意のフィールドにパーテーションを貼る場合に、そのフィールドのデータ型を指定します。
BigQuery SQL table clustering
省略可の項目です。
フィールドを物理的に整理(並べ替え)したいときに指定します。うまく指定することで、クエリ効率が良くなる可能性があります。
Maximum number of synced documents per second
1秒あたりに同期するドキュメント数の指定です。デフォルトでは100になっていますが、大規模なサービスだと300,500,1000など指定すると良いかと思います。
あまりに大きくしすぎるとリソースの過負荷が少し心配ですので、データの取り込みにかかる時間とコストの兼ね合いで検討します。
Backup Collection Name
省略可の項目です。
FirestoreからBigQuery側にうまく流せなかったときのログを取っておきたい場合は、そのログを格納するコレクション名を指定します。
Transform function URL
省略可の項目です。
BigQueryに書き込む際に使うFunctionsの関数を指定したい場合に記述します。
Use new query syntax for snapshots
新バージョンのクエリ構文を使うか否かの選択肢です。
特定の互換性を意識しなければいけない場合以外はYesで良いかと思いますが、状況を加味して判断します。
Exclude old data payloads
古いデータ(変更履歴)を除外するか否かの設定です。
常に最新のデータだけあれば良い場合を除くと、おそらくだいたいのデータ解析のシーンでは必要な気がしますので、わからなければ一旦No(除外しない)のままが良いかと思います。
Cloud KMS key name
省略可の項目です。
暗号化キーを独自で管理したい場合のみ設定します。
Maximum number of enqueue attempts
省略可の項目です。
データを流す際のリトライ回数(キューに登録する回数)を指定します。より安定的に運用したい場合は数値を上げると良いかもしれません。今のところデフォルトの3で困ったことはありません。
4. 拡張機能をインストールする
最後に「拡張機能をインストールする」ボタンを押下すると、インストールが始まります。
だいたい5分〜10分程度で構成が完了し、それ以降に追加編集されたデータは自動的にBigQuery側へ流れることになります。
Firestore上にある既存のデータをBigQueryへエクスポートする
拡張機能を利用した方法では、設定以降のデータはBigQueryに流れていきますが、設定以前の既存のデータは流れません。
つまり拡張機能を導入したあと、一度だけ手動で既存データをエクスポートする必要がありますので、手順を簡単にメモしておきます。
1. ターミナルからFirebaseへログイン
gcloud auth application-default login2. インポートコマンドを叩く
npx @firebaseextensions/fs-bq-import-collection3. 設問に答えていく
質問形式で進んでいくため、状況に合った回答をしていくと、最終的に自動でエクスポートされます。
usersコレクションのデータを、BigQuery側のfirestore_exportデータセットへエクスポートする際のサンプルが下記になります。
? What is your Firebase project ID? xxx
? What is your BigQuery project ID? xxx
? What is the path of the the Cloud Firestore Collection you would like to impor
t from? (This may, or may not, be the same Collection for which you plan to mirr
or changes.) users
? Would you like to import documents via a Collection Group query? No
? What is the ID of the BigQuery dataset that you would like to use? (A dataset
will be created if it doesn't already exist) firestore_export
? What is the identifying prefix of the BigQuery table that you would like to im
port to? (A table will be created if one doesn't already exist) users
? How many documents should the import stream into BigQuery at once? 300
? Where would you like the BigQuery dataset to be located? asia-northeast1
? Would you like to run the import across multiple threads? No
? Would you like to use the new optimized snapshot query script? No
? Would you like to use a local firestore emulator? No注意点があるとすれば、データ量があまりに多い(数十万〜百万件とか)場合は、「How many documents should the import stream into BigQuery at once」が300だと日が暮れます。
(終業間近に開始してしまって絶望したことがあります。)
ここはリソースとの兼ね合いにもなりますが、ある程度大きな数値を指定しておくと良いかと思います。
このエクスポート処理が完了すれば、過去のデータも含めて分析できる情報がBigQueryに貯まっていくことになります。
BigQuery側にビューを作成する
BigQuery側に流し込まれる情報は、デフォルトではコレクション内のフィールドがjson形式になっています。
jsonを解いて見やすくしなければ分析しづらいため、BigQuery上にビューを作成します。(ビューは元データを参照して、取り扱いやすいように整形できるものです)
例えば下記のような形式になります。
CREATE OR REPLACE VIEW `プロジェクトID.analysis_table.users_view` AS
SELECT
operation,
timestamp,
JSON_EXTRACT_SCALAR(data, '$.id') AS id,
JSON_EXTRACT_SCALAR(data, '$.gender') AS gender,
TIMESTAMP(TIMESTAMP_ADD(
TIMESTAMP_SECONDS(CAST(JSON_EXTRACT_SCALAR(data, '$.registrationDateTime._seconds') AS INT64)),
INTERVAL CAST(FLOOR(CAST(JSON_EXTRACT_SCALAR(data, '$.registrationDateTime._nanoseconds') AS INT64) / 1000) AS INT64) MICROSECOND
)) AS registrationDateTime
FROM
`プロジェクトID.firestore_export.users_raw_changelog`;FROMに参照元のデータを指定して、jsonから取り出したいフィールド名を指定してビューを作成する形です。
ビューは一度作成しておけば何度でも使用できます。
BigQueryのデータをLooker Studioに取り込んでレポートを作成する
これでBigQueryのデータを取り扱えるようになりましたので、Looker Studioでデータをビジュアライズして分析しやすいように整えていきます。レポートを作成しましょう。
Looker Studioは基本無料で使える割に高機能なサービスで、BigQueryだけでなくGoogle AnalyticsやGoogle Search Consoleなどのデータからも引っ張って来れたりします。
費用も基本無料で、参照元の課金が発生します。(つまりBigQueryのデータを参照する場合は、参照する際にかかったクエリ料金が課金されるような形になります。)
今回はBigQueryのデータで表を作るような簡単な方法について解説していきます。
1. Looker Studioにログインして新規レポートを作成
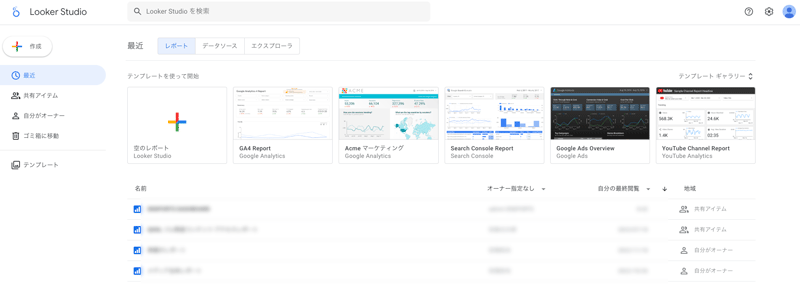
まずはLooker Studio公式サイトからGoogleアカウントでログイン。
下記のような画面になりますので、左上の「作成」から「レポート」を選択します。
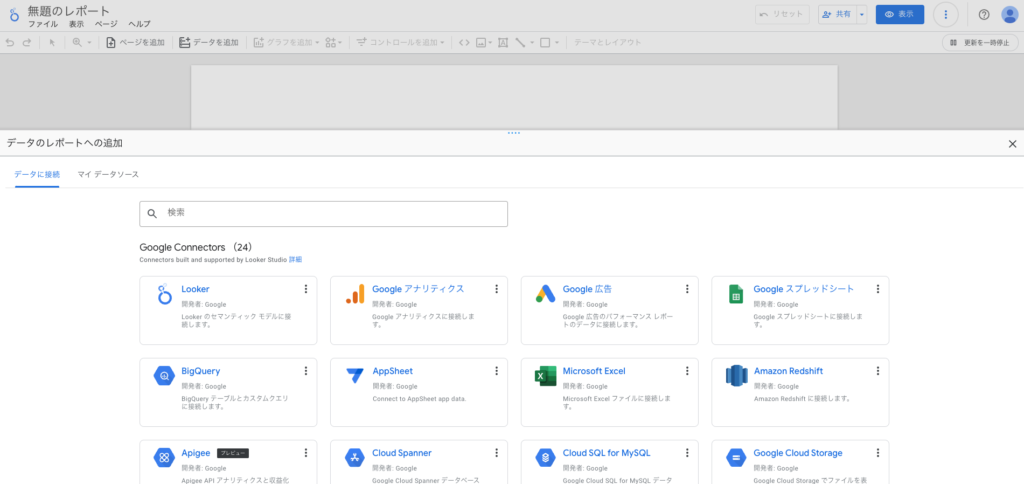
2. データソースを選択
次にデータソースを選びます。今回はBigQueryのデータを使いますから、Google Connectors内にあるBigQueryを選択。
3. 使用するテーブルを選択
次の画面では、BigQuery内にあるプロジェクト、データセット、テーブルを順に選択します。
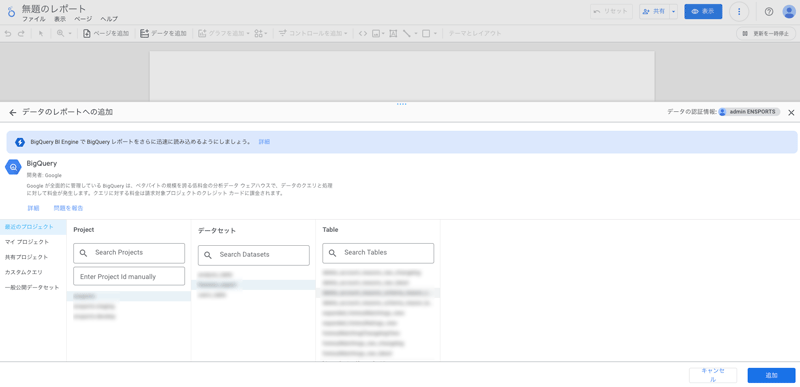
選択し終わったら「追加」を押下すれば、レポートが作成されます。
4. レポートを作成する
あとは好きなようにレポートを作成します。表やレポートを組み合わせて、日次の動きを追ったり、ユーザごとのアクティビティを可視化したりと、必要なデータ分析をおこなってください。
FirestoreとBigQueryの連携はちょっと複雑
例えばGoogle AnalyticsとLookerを連携するような形はとてもシンプルなのですが、Firestoreのデータをつかって分析するときはちょっと手間がかかります。
最初調べたときに大変でしたので、メモ代わりに残しました。
どなたかのお役に立てば幸いです。
カジュアルにお話しませんか?
エンスポーツでは、一緒にはたらく仲間を募集しています。
アプリ開発に携わっていただけるエンジニアはもちろん、広告集客・ライティングが得意なディレクターやマーケターの方も歓迎しています。
ご興味をもっていただけましたら、ぜひ気軽にご連絡ください。
記事を書いた人
Takuya Takubo
Develop / PdM / 田窪 拓也